Introducing dbt-impala
As part of my new role at Cloudera, I have been looking at a tool called dbt.
To many, dbt needs no introduction - it has not just made a splash in the data ecosystem, it has come in riding a tsunami of positivity, and for good reason!
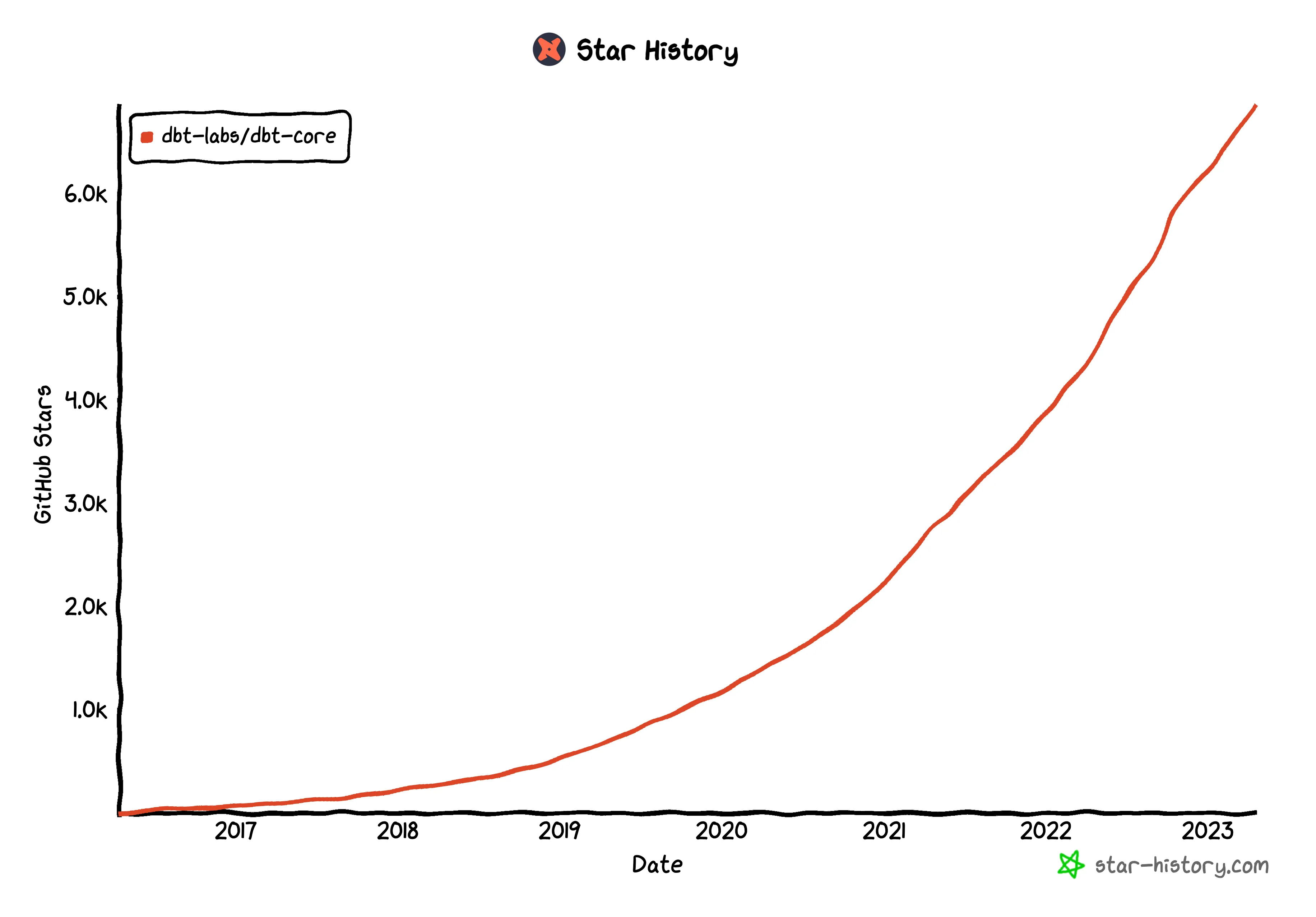
Just looking at it’s star history we can see it’s adoption is only getting faster and faster - I don’t see that changing any time soon. It is quickly becoming synonymous with the Modern Data Stack.
What is dbt?
If you haven’t come across dbt before, it doesn’t always sound very exciting - I’ve heard some folks compare it to saving SQL scripts in GitHub, which I suppose isn’t a million miles off, but there’s a lot more to it than that!
To quote dbtLabs:
dbt also enables analysts to work more like software engineers
dbt essentially allows you to create your analytics projects using the same processes that software projects have been using for years now.
In software, there’s a lot of concepts that every single team knows and uses;
- collobrative development
- version control
- don’t repeat yourself (DRY)
- documentation
- testing
How many analytics projects utilise these things? In my experience, it’s very few - and that’s not because they don’t see the value of it, it’s because there has been very little capability to reliably implement these ideas in the analytics space.
Many analytics teams have lived this pain; work ends up silod in a member’s ‘user’ space, queries end up being written more than once by different members (often with varying levels of optimisation), and after a year of hard work - there is little, if any, documentation to bring on new team members.
dbt finally enables analytics teams to fully leverage these concepts in their workflows.
Read more straight from the horses mouth.
dbt and Impala
Cloudera provides several different engines that analytics teams can use - Impala, Hive and Spark. These engines serve different use cases & target users, though there is some overlap.
Impala is a fan-favourite for ad-hoc, low-latency analytics over vast datasets that go up to & beyond the petabyte scale. We saw a lot of demand for using dbt with Impala to assist analytics teams in re-structuring how they organise their projects.
As such, our small and brand new team (we’re hiring btw!) has been hard at work building out this functionality, to bring dbt to Apache Impala & Cloudera Data Platform.
In just a few weeks, we have gone from a blank canvas to a functional adapter that is already being used in the real world. We are targetting a new release every week to continue adding the standard dbt features that users expect.
The good news - it’s all 100% free & open source!
Get dbt-impala
You can find the dbt-impala on GitHub here.
It’s available via PyPi & can be installed with pip
pip install dbt-impala
If you have any feedback or questions, please reach out to innovation-feedback@cloudera.com or myself!